#remove resources from docker
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Mobile Tumblr US users spend an average of 4.04 minutes per session on the app.
Note
so I saw that you work with Krita when it comes to your art. Do you have any tips when it comes the app? I have just started using it.
Sure!
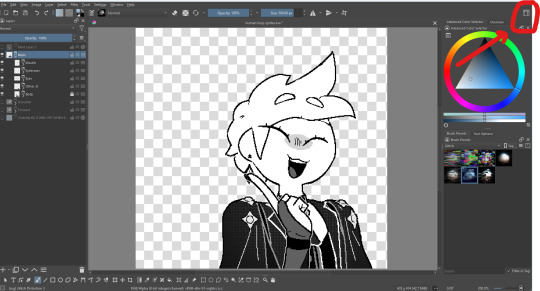
Up here is your workspaces tab where you can switch between different layouts. You can also adjust, make, and save your own layouts until you find the perfect orientation that you're most comfortable with.
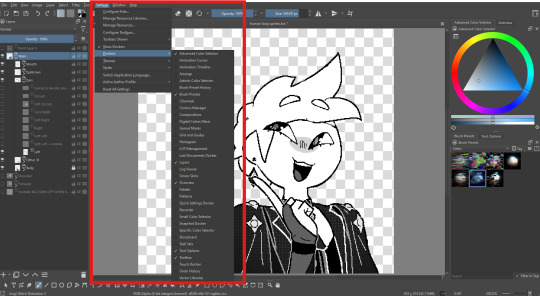
If you go to Settings -> Dockers, you can see all the different widgets (?) that you can add to your layout.

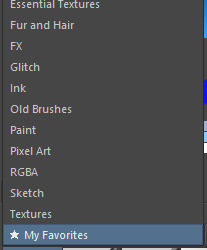
You can right click on brushes to add/remove them from tags to help you organize.
Here's a resource for adding and finding new brushes
If you want to use Krita to animate, I would recommend reading this beforehand because Krita is still working on implementing rendering and you need to download an extension to do that.
Since I don't know your familiarity with digital drawing programs in general I don't know what to explain, a lot of the things in Krita can be traced back and forth with other drawing programs, things are just in different places which poking around the program can help you find
if anyone has any other tips please feel free to add!
43 notes
·
View notes
Text
Unleashing Efficiency: Containerization with Docker
Introduction: In the fast-paced world of modern IT, agility and efficiency reign supreme. Enter Docker - a revolutionary tool that has transformed the way applications are developed, deployed, and managed. Containerization with Docker has become a cornerstone of contemporary software development, offering unparalleled flexibility, scalability, and portability. In this blog, we'll explore the fundamentals of Docker containerization, its benefits, and practical insights into leveraging Docker for streamlining your development workflow.
Understanding Docker Containerization: At its core, Docker is an open-source platform that enables developers to package applications and their dependencies into lightweight, self-contained units known as containers. Unlike traditional virtualization, where each application runs on its own guest operating system, Docker containers share the host operating system's kernel, resulting in significant resource savings and improved performance.
Key Benefits of Docker Containerization:
Portability: Docker containers encapsulate the application code, runtime, libraries, and dependencies, making them portable across different environments, from development to production.
Isolation: Containers provide a high degree of isolation, ensuring that applications run independently of each other without interference, thus enhancing security and stability.
Scalability: Docker's architecture facilitates effortless scaling by allowing applications to be deployed and replicated across multiple containers, enabling seamless horizontal scaling as demand fluctuates.
Consistency: With Docker, developers can create standardized environments using Dockerfiles and Docker Compose, ensuring consistency between development, testing, and production environments.
Speed: Docker accelerates the development lifecycle by reducing the time spent on setting up development environments, debugging compatibility issues, and deploying applications.
Getting Started with Docker: To embark on your Docker journey, begin by installing Docker Desktop or Docker Engine on your development machine. Docker Desktop provides a user-friendly interface for managing containers, while Docker Engine offers a command-line interface for advanced users.
Once Docker is installed, you can start building and running containers using Docker's command-line interface (CLI). The basic workflow involves:
Writing a Dockerfile: A text file that contains instructions for building a Docker image, specifying the base image, dependencies, environment variables, and commands to run.
Building Docker Images: Use the docker build command to build a Docker image from the Dockerfile.
Running Containers: Utilize the docker run command to create and run containers based on the Docker images.
Managing Containers: Docker provides a range of commands for managing containers, including starting, stopping, restarting, and removing containers.
Best Practices for Docker Containerization: To maximize the benefits of Docker containerization, consider the following best practices:
Keep Containers Lightweight: Minimize the size of Docker images by removing unnecessary dependencies and optimizing Dockerfiles.
Use Multi-Stage Builds: Employ multi-stage builds to reduce the size of Docker images and improve build times.
Utilize Docker Compose: Docker Compose simplifies the management of multi-container applications by defining them in a single YAML file.
Implement Health Checks: Define health checks in Dockerfiles to ensure that containers are functioning correctly and automatically restart them if they fail.
Secure Containers: Follow security best practices, such as running containers with non-root users, limiting container privileges, and regularly updating base images to patch vulnerabilities.
Conclusion: Docker containerization has revolutionized the way applications are developed, deployed, and managed, offering unparalleled agility, efficiency, and scalability. By embracing Docker, developers can streamline their development workflow, accelerate the deployment process, and improve the consistency and reliability of their applications. Whether you're a seasoned developer or just getting started, Docker opens up a world of possibilities, empowering you to build and deploy applications with ease in today's fast-paced digital landscape.
For more details visit www.qcsdclabs.com
#redhat#linux#docker#aws#agile#agiledevelopment#container#redhatcourses#information technology#ContainerSecurity#ContainerDeployment#DockerSwarm#Kubernetes#ContainerOrchestration#DevOps
5 notes
·
View notes
Text
WILL CONTAINER REPLACE HYPERVISOR
As with the increasing technology, the way data centers operate has changed over the years due to virtualization. Over the years, different software has been launched that has made it easy for companies to manage their data operating center. This allows companies to operate their open-source object storage data through different operating systems together, thereby maximizing their resources and making their data managing work easy and useful for their business.
Understanding different technological models to their programming for object storage it requires proper knowledge and understanding of each. The same holds for containers as well as hypervisor which have been in the market for quite a time providing companies with different operating solutions.
Let’s understand how they work
Virtual machines- they work through hypervisor removing hardware system and enabling to run the data operating systems.
Containers- work by extracting operating systems and enable one to run data through applications and they have become more famous recently.

Although container technology has been in use since 2013, it became more engaging after the introduction of Docker. Thereby, it is an open-source object storage platform used for building, deploying and managing containerized applications.
The container’s system always works through the underlying operating system using virtual memory support that provides basic services to all the applications. Whereas hypervisors require their operating system for working properly with the help of hardware support.
Although containers, as well as hypervisors, work differently, have distinct and unique features, both the technologies share some similarities such as improving IT managed service efficiency. The profitability of the applications used and enhancing the lifecycle of software development.
And nowadays, it is becoming a hot topic and there is a lot of discussion going on whether containers will take over and replace hypervisors. This has been becoming of keen interest to many people as some are in favor of containers and some are with hypervisor as both the technologies have some particular properties that can help in solving different solutions.
Let’s discuss in detail and understand their functioning, differences and which one is better in terms of technology?
What are virtual machines?
Virtual machines are software-defined computers that run with the help of cloud hosting software thereby allowing multiple applications to run individually through hardware. They are best suited when one needs to operate different applications without letting them interfere with each other.
As the applications run differently on VMs, all applications will have a different set of hardware, which help companies in reducing the money spent on hardware management.
Virtual machines work with physical computers by using software layers that are light-weighted and are called a hypervisor.
A hypervisor that is used for working virtual machines helps in providing fresh service by separating VMs from one another and then allocating processors, memory and storage among them. This can be used by cloud hosting service providers in increasing their network functioning on nodes that are expensive automatically.
Hypervisors allow host machines to have different operating systems thereby allowing them to operate many virtual machines which leads to the maximum use of their resources such as bandwidth and memory.

What is a container?
Containers are also software-defined computers but they operate through a single host operating system. This means all applications have one operating center that allows it to access from anywhere using any applications such as a laptop, in the cloud etc.
Containers use the operating system (OS) virtualization form, that is they use the host operating system to perform their function. The container includes all the code, dependencies and operating system by itself allowing it to run from anywhere with the help of cloud hosting technology.
They promised methods of implementing infrastructure requirements that were streamlined and can be used as an alternative to virtual machines.
Even though containers are known to improve how cloud platforms was developed and deployed, they are still not as secure as VMs.
The same operating system can run different containers and can share their resources and they further, allow streamlining of implemented infrastructure requirements by the system.
Now as we have understood the working of VMs and containers, let’s see the benefits of both the technologies
Benefits of virtual machines
They allow different operating systems to work in one hardware system that maintains energy costs and rack space to cooling, thereby allowing economical gain in the cloud.
This technology provided by cloud managed services is easier to spin up and down and it is much easier to create backups with this system.
Allowing easy backups and restoring images, it is easy and simple to recover from disaster recovery.
It allows the isolated operating system, hence testing of applications is relatively easy, free and simple.

Benefits of containers:
They are light in weight and hence boost significantly faster as compared to VMs within a few seconds and require hardware and fewer operating systems.
They are portable cloud hosting data centers that can be used to run from anywhere which means the cause of the issue is being reduced.
They enable micro-services that allow easy testing of applications, failures related to the single point are reduced and the velocity related to development is increased.
Let’s see the difference between containers and VMs
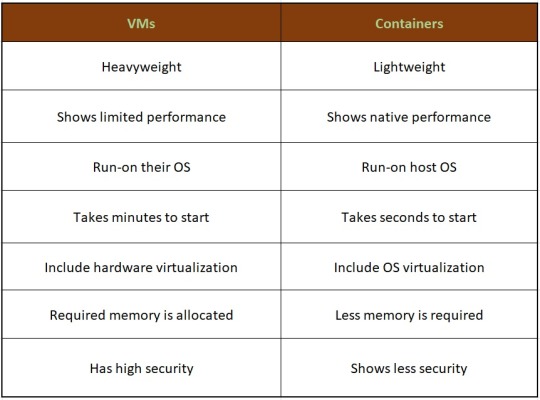
Hence, looking at all these differences one can make out that, containers have added advantage over the old virtualization technology. As containers are faster, more lightweight and easy to manage than VMs and are way beyond these previous technologies in many ways.
In the case of hypervisor, virtualization is performed through physical hardware having a separate operating system that can be run on the same physical carrier. Hence each hardware requires a separate operating system to run an application and its associated libraries.
Whereas containers virtualize operating systems instead of hardware, thereby each container only contains the application, its library and dependencies.
Containers in a similar way to a virtual machine will allow developers to improve the CPU and use physical machines' memory. Containers through their managed service provider further allow microservice architecture, allowing application components to be deployed and scaled more granularly.

As we have seen the benefits and differences between the two technologies, one must know when to use containers and when to use virtual machines, as many people want to use both and some want to use either of them.
Let’s see when to use hypervisor for cases such as:
Many people want to continue with the virtual machines as they are compatible and consistent with their use and shifting to containers is not the case for them.
VMs provide a single computer or cloud hosting server to run multiple applications together which is only required by most people.
As containers run on host operating systems which is not the case with VMs. Hence, for security purposes, containers are not that safe as they can destroy all the applications together. However, in the case of virtual machines as it includes different hardware and belongs to secure cloud software, so only one application will be damaged.
Container’s turn out to be useful in case of,
Containers enable DevOps and microservices as they are portable and fast, taking microseconds to start working.
Nowadays, many web applications are moving towards a microservices architecture that helps in building web applications from managed service providers. The containers help in providing this feature making it easy for updating and redeploying of the part needed of the application.
Containers contain a scalability property that automatically scales containers, reproduces container images and spin them down when they are not needed.
With increasing technology, people want to move to technology that is fast and has speed, containers in this scenario are way faster than a hypervisor. That also enables fast testing and speed recovery of images when a reboot is performed.

Hence, will containers replace hypervisor?
Although both the cloud hosting technologies share some similarities, both are different from each other in one or the other aspect. Hence, it is not easy to conclude. Before making any final thoughts about it, let's see a few points about each.

Still, a question can arise in mind, why containers?
Although, as stated above there are many reasons to still use virtual machines, containers provide flexibility and portability that is increasing its demand in the multi-cloud platform world and the way they allocate their resources.
Still today many companies do not know how to deploy their new applications when installed, hence containerizing applications being flexible allow easy handling of many clouds hosting data center software environments of modern IT technology.
These containers are also useful for automation and DevOps pipelines including continuous integration and continuous development implementation. This means containers having small size and modularity of building it in small parts allows application buildup completely by stacking those parts together.
They not only increase the efficiency of the system and enhance the working of resources but also save money by preferring for operating multiple processes.
They are quicker to boost up as compared to virtual machines that take minutes in boosting and for recovery.
Another important point is that they have a minimalistic structure and do not need a full operating system or any hardware for its functioning and can be installed and removed without disturbing the whole system.
Containers replace the patching process that was used traditionally, thereby allowing many organizations to respond to various issues faster and making it easy for managing applications.
As containers contain an operating system abstract that operates its operating system, the virtualization problem that is being faced in the case of virtual machines is solved as containers have virtual environments that make it easy to operate different operating systems provided by vendor management.
Still, virtual machines are useful to many
Although containers have more advantages as compared to virtual machines, still there are a few disadvantages associated with them such as security issues with containers as they belong to disturbed cloud software.
Hacking a container is easy as they are using single software for operating multiple applications which can allow one to excess whole cloud hosting system if breaching occurs which is not the case with virtual machines as they contain an additional barrier between VM, host server and other virtual machines.
In case the fresh service software gets affected by malware, it spreads to all the applications as it uses a single operating system which is not the case with virtual machines.
People feel more familiar with virtual machines as they are well established in most organizations for a long time and businesses include teams and procedures that manage the working of VMs such as their deployment, backups and monitoring.
Many times, companies prefer working with an organized operating system type of secure cloud software as one machine, especially for applications that are complex to understand.
Conclusion
Concluding this blog, the final thought is that, as we have seen, both the containers and virtual machine cloud hosting technologies are provided with different problem-solving qualities. Containers help in focusing more on building code, creating better software and making applications work on a faster note whereas, with virtual machines, although they are slower, less portable and heavy still people prefer them in provisioning infrastructure for enterprise, running legacy or any monolithic applications.
Stating that, if one wants to operate a full operating system, they should go for hypervisor and if they want to have service from a cloud managed service provider that is lightweight and in a portable manner, one must go for containers.
Hence, it will take time for containers to replace virtual machines as they are still needed by many for running some old-style applications and host multiple operating systems in parallel even though VMs has not had so cloud-native servers. Therefore, it can be said that they are not likely to replace virtual machines as both the technologies complement each other by providing IT managed services instead of replacing each other and both the technologies have a place in the modern data center.
For more insights do visit our website
#container #hypervisor #docker #technology #zybisys #godaddy
6 notes
·
View notes
Text
Using Docker for Full Stack Development and Deployment

1. Introduction to Docker
What is Docker? Docker is an open-source platform that automates the deployment, scaling, and management of applications inside containers. A container packages your application and its dependencies, ensuring it runs consistently across different computing environments.
Containers vs Virtual Machines (VMs)
Containers are lightweight and use fewer resources than VMs because they share the host operating system’s kernel, while VMs simulate an entire operating system. Containers are more efficient and easier to deploy.
Docker containers provide faster startup times, less overhead, and portability across development, staging, and production environments.
Benefits of Docker in Full Stack Development
Portability: Docker ensures that your application runs the same way regardless of the environment (dev, test, or production).
Consistency: Developers can share Dockerfiles to create identical environments for different developers.
Scalability: Docker containers can be quickly replicated, allowing your application to scale horizontally without a lot of overhead.
Isolation: Docker containers provide isolated environments for each part of your application, ensuring that dependencies don’t conflict.
2. Setting Up Docker for Full Stack Applications
Installing Docker and Docker Compose
Docker can be installed on any system (Windows, macOS, Linux). Provide steps for installing Docker and Docker Compose (which simplifies multi-container management).
Commands:
docker --version to check the installed Docker version.
docker-compose --version to check the Docker Compose version.
Setting Up Project Structure
Organize your project into different directories (e.g., /frontend, /backend, /db).
Each service will have its own Dockerfile and configuration file for Docker Compose.
3. Creating Dockerfiles for Frontend and Backend
Dockerfile for the Frontend:
For a React/Angular app:
Dockerfile
FROM node:14 WORKDIR /app COPY package*.json ./ RUN npm install COPY . . EXPOSE 3000 CMD ["npm", "start"]
This Dockerfile installs Node.js dependencies, copies the application, exposes the appropriate port, and starts the server.
Dockerfile for the Backend:
For a Python Flask app
Dockerfile
FROM python:3.9 WORKDIR /app COPY requirements.txt . RUN pip install -r requirements.txt COPY . . EXPOSE 5000 CMD ["python", "app.py"]
For a Java Spring Boot app:
Dockerfile
FROM openjdk:11 WORKDIR /app COPY target/my-app.jar my-app.jar EXPOSE 8080 CMD ["java", "-jar", "my-app.jar"]
This Dockerfile installs the necessary dependencies, copies the code, exposes the necessary port, and runs the app.
4. Docker Compose for Multi-Container Applications
What is Docker Compose? Docker Compose is a tool for defining and running multi-container Docker applications. With a docker-compose.yml file, you can configure services, networks, and volumes.
docker-compose.yml Example:
yaml
version: "3" services: frontend: build: context: ./frontend ports: - "3000:3000" backend: build: context: ./backend ports: - "5000:5000" depends_on: - db db: image: postgres environment: POSTGRES_USER: user POSTGRES_PASSWORD: password POSTGRES_DB: mydb
This YAML file defines three services: frontend, backend, and a PostgreSQL database. It also sets up networking and environment variables.
5. Building and Running Docker Containers
Building Docker Images:
Use docker build -t <image_name> <path> to build images.
For example:
bash
docker build -t frontend ./frontend docker build -t backend ./backend
Running Containers:
You can run individual containers using docker run or use Docker Compose to start all services:
bash
docker-compose up
Use docker ps to list running containers, and docker logs <container_id> to check logs.
Stopping and Removing Containers:
Use docker stop <container_id> and docker rm <container_id> to stop and remove containers.
With Docker Compose: docker-compose down to stop and remove all services.
6. Dockerizing Databases
Running Databases in Docker:
You can easily run databases like PostgreSQL, MySQL, or MongoDB as Docker containers.
Example for PostgreSQL in docker-compose.yml:
yaml
db: image: postgres environment: POSTGRES_USER: user POSTGRES_PASSWORD: password POSTGRES_DB: mydb
Persistent Storage with Docker Volumes:
Use Docker volumes to persist database data even when containers are stopped or removed:
yaml
volumes: - db_data:/var/lib/postgresql/data
Define the volume at the bottom of the file:
yaml
volumes: db_data:
Connecting Backend to Databases:
Your backend services can access databases via Docker networking. In the backend service, refer to the database by its service name (e.g., db).
7. Continuous Integration and Deployment (CI/CD) with Docker
Setting Up a CI/CD Pipeline:
Use Docker in CI/CD pipelines to ensure consistency across environments.
Example: GitHub Actions or Jenkins pipeline using Docker to build and push images.
Example .github/workflows/docker.yml:
yaml
name: CI/CD Pipeline on: [push] jobs: build: runs-on: ubuntu-latest steps: - name: Checkout Code uses: actions/checkout@v2 - name: Build Docker Image run: docker build -t myapp . - name: Push Docker Image run: docker push myapp
Automating Deployment:
Once images are built and pushed to a Docker registry (e.g., Docker Hub, Amazon ECR), they can be pulled into your production or staging environment.
8. Scaling Applications with Docker
Docker Swarm for Orchestration:
Docker Swarm is a native clustering and orchestration tool for Docker. You can scale your services by specifying the number of replicas.
Example:
bash
docker service scale myapp=5
Kubernetes for Advanced Orchestration:
Kubernetes (K8s) is more complex but offers greater scalability and fault tolerance. It can manage Docker containers at scale.
Load Balancing and Service Discovery:
Use Docker Swarm or Kubernetes to automatically load balance traffic to different container replicas.
9. Best Practices
Optimizing Docker Images:
Use smaller base images (e.g., alpine images) to reduce image size.
Use multi-stage builds to avoid unnecessary dependencies in the final image.
Environment Variables and Secrets Management:
Store sensitive data like API keys or database credentials in Docker secrets or environment variables rather than hardcoding them.
Logging and Monitoring:
Use tools like Docker’s built-in logging drivers, or integrate with ELK stack (Elasticsearch, Logstash, Kibana) for advanced logging.
For monitoring, tools like Prometheus and Grafana can be used to track Docker container metrics.
10. Conclusion
Why Use Docker in Full Stack Development? Docker simplifies the management of complex full-stack applications by ensuring consistent environments across all stages of development. It also offers significant performance benefits and scalability options.
Recommendations:
Encourage users to integrate Docker with CI/CD pipelines for automated builds and deployment.
Mention the use of Docker for microservices architecture, enabling easy scaling and management of individual services.
WEBSITE: https://www.ficusoft.in/full-stack-developer-course-in-chennai/
0 notes
Text
Cost Optimization in the Cloud: Reducing Expenses Without Sacrificing Performance
Introduction
Cloud computing offers scalability and flexibility, but without careful management, costs can spiral out of control. Businesses must find ways to optimize cloud spending while maintaining high performance. Cost optimization in the cloud is about eliminating waste, optimizing resources, and leveraging automation to reduce expenses without sacrificing efficiency or reliability.
In this blog, we’ll explore key strategies to cut cloud costs while ensuring optimal performance.
Why Cloud Cost Optimization Matters
Uncontrolled cloud spending can lead to budget overruns and wasted resources. Organizations must implement cost-saving measures to: ✅ Maximize ROI – Get the most value from cloud investments. ✅ Improve Efficiency – Eliminate unnecessary resource consumption. ✅ Enhance Scalability – Pay only for what’s needed while ensuring performance. ✅ Strengthen Governance – Maintain visibility and control over cloud expenses.
Top Cloud Cost Optimization Strategies
1. Right-Sizing Resources to Match Workloads
One of the biggest causes of cloud overspending is using over-provisioned instances. Right-sizing ensures that resources are aligned with actual workloads.
✔ Analyze CPU, memory, and storage usage to select optimal instance sizes. ✔ Use auto-scaling to adjust resources dynamically. ✔ Choose spot instances or reserved instances for predictable workloads.
Recommended Tools: AWS Compute Optimizer, Azure Advisor, Google Cloud Recommender
2. Implement Auto-Scaling to Avoid Over-Provisioning
Auto-scaling ensures that cloud resources increase or decrease based on real-time demand. This prevents paying for unused capacity while maintaining performance.
✔ Configure horizontal scaling to add or remove instances as needed. ✔ Implement vertical scaling to adjust resource allocation dynamically. ✔ Use scheduled scaling for predictable traffic fluctuations.
Recommended Tools: AWS Auto Scaling, Kubernetes Horizontal Pod Autoscaler, Azure Virtual Machine Scale Sets
3. Optimize Storage Costs with Tiered Storage and Data Lifecycle Policies
Storing inactive or infrequently accessed data in expensive storage tiers can lead to unnecessary costs.
✔ Move cold data to cost-effective storage options (e.g., AWS Glacier, Azure Blob Cool Storage). ✔ Set data lifecycle policies to archive or delete unused files automatically. ✔ Use compression and deduplication to reduce storage footprint.
Recommended Tools: AWS S3 Lifecycle Policies, Azure Storage Tiers, Google Cloud Storage Nearline
4. Use Serverless Computing to Reduce Infrastructure Costs
Serverless computing eliminates the need for provisioning and managing servers, allowing businesses to pay only for actual usage.
✔ Adopt AWS Lambda, Azure Functions, or Google Cloud Functions for event-driven workloads. ✔ Use containerization (Kubernetes, Docker) to maximize resource efficiency. ✔ Implement event-based architectures to trigger functions only when needed.
5. Monitor and Analyze Cloud Costs Regularly
Without real-time cost monitoring, organizations can quickly lose track of spending.
✔ Set up budget alerts to track cloud expenses. ✔ Analyze spending patterns using cost and usage reports. ✔ Identify underutilized resources and shut them down.
Recommended Tools: AWS Cost Explorer, Azure Cost Management, Google Cloud Billing Reports
6. Adopt a FinOps Approach for Cloud Financial Management
FinOps (Financial Operations) is a collaborative approach that helps organizations like Salzen optimize cloud spending through accountability and cost governance.
✔ Set budgets and enforce spending limits for different teams. ✔ Tag resources for better cost allocation and reporting. ✔ Encourage cross-team collaboration between finance, operations, and development teams.
Recommended Tools: CloudHealth, Apptio Cloudability, AWS Budgets
7. Leverage Discounts and Savings Plans
Cloud providers offer various discounted pricing models for committed usage.
✔ Use Reserved Instances (RIs) for long-term workloads. ✔ Take advantage of Savings Plans for flexible, discounted pricing. ✔ Utilize Spot Instances for non-critical, batch-processing tasks.
Recommended Tools: AWS Savings Plans, Azure Reserved VM Instances, Google Committed Use Discounts
Balancing Cost Optimization and Performance
While reducing costs is important, businesses must ensure performance remains uncompromised. Here’s how:
🚀 Prioritize mission-critical workloads while optimizing non-essential ones. 🚀 Use load balancing to distribute workloads efficiently. 🚀 **Continuously refine cost.
0 notes
Text
Mastering Docker with LabEx: Your Gateway to Seamless Containerization
Docker has revolutionized how developers and IT professionals manage, deploy, and scale applications. Its containerization technology simplifies workflows, enhances scalability, and ensures consistent environments across development and production. At LabEx, we provide an intuitive platform to learn and practice Docker commands, making the journey from beginner to expert seamless. Here's how LabEx can empower you to master Docker.
What is Docker?
Docker is an open-source platform that automates the deployment of applications inside lightweight, portable containers. These containers bundle everything needed to run an application, including libraries, dependencies, and configurations, ensuring smooth operation across various computing environments.
With Docker, you can:
Eliminate environment inconsistencies.
Accelerate software delivery cycles.
Enhance resource utilization through container isolation.
Why Learn Docker?
Understanding Docker is crucial for anyone working in modern software development or IT operations. Proficiency in Docker opens opportunities in DevOps, cloud computing, and microservices architecture. Key benefits of learning Docker include:
Streamlined Development Workflow: Develop, test, and deploy applications efficiently.
Scalability and Portability: Run your containers across any environment without additional configuration.
Integration with DevOps Tools: Use Docker with CI/CD pipelines for continuous integration and deployment.
LabEx: The Ultimate Online Docker Playground
At LabEx, we provide an interactive Docker Playground that caters to learners of all levels. Whether you're just starting or looking to refine advanced skills, LabEx offers a structured approach with real-world projects and practical exercises.
Features of LabEx Docker Playground
Hands-On Learning: Dive into real-world Docker scenarios with guided tutorials. LabEx's environment allows you to practice essential Docker commands and workflows, such as container creation, image management, and network configuration.
Interactive Labs: Gain practical experience with our Online Docker Playground. From running basic commands to building custom images, every exercise reinforces your understanding and builds your confidence.
Comprehensive Course Material: Our content covers everything from basic Docker commands to advanced topics like container orchestration and integration with Kubernetes.
Project-Based Approach: Work on projects that mimic real-life scenarios, such as deploying microservices, scaling applications, and creating automated workflows.
Community Support: Collaborate and learn with a global community of tech enthusiasts and professionals. Share your progress, ask questions, and exchange insights.
Essential Skills You’ll Learn
By completing the Docker Skill Tree on LabEx, you’ll master key aspects, including:
Container Management: Learn to create, manage, and remove containers effectively.
Image Building: Understand how to build and optimize Docker images for efficiency.
Networking and Security: Configure secure communication between containers.
Volume Management: Persist data across containers using volumes.
Integration with CI/CD Pipelines: Automate deployments for faster delivery.
Why Choose LabEx for Docker Training?
Flexible Learning: Learn at your own pace, with no time constraints.
Practical Focus: Our labs emphasize doing, not just reading.
Cost-Effective: Access high-quality training without breaking the bank.
Real-Time Feedback: Immediate feedback on your exercises ensures you're always improving.
Kickstart Your Docker Journey Today
Mastering Docker opens doors to countless opportunities in DevOps, cloud computing, and application development. With LabEx, you can confidently acquire the skills needed to thrive in this container-driven era. Whether you're a developer, IT professional, or student, our platform ensures a rewarding learning experience.
0 notes
Link
This. 100% this. I run PiHole (an at-home DNS server), which is basically replacing a fundamental component of the whole damn Internet in order to block ads. When any device on my network reaches out and tries to download an ad, the PiHole lies to it and says “I don’t know her, sorry 💅🏼”. End result, you can block ads on devices you normally have no control over like smart tvs and stuff. This is like. the nuclear option for adblocking.
I cannot stress enough how satisfying it is to see blank spaces where ads used to be on your Roku homescreen. I ALSO cannot stress enough how complicated and frustrating this setup can be. I have to mess around with docker containers, and router settings, and device custom networking settings, and troubleshoot if it’s part of the reason my internet just stopped working, or why certain ads got through. And the worst part? Sometimes the ads got through because the companies whose services you use actually own the advertising networks too, and they did things that made blocking their ads with PiHole impossible unless you also break their service (looking at you, fucking Facebook/IG/YouTube).
Even device manufacturers are starting to wise up to this tactic and hardcoding specific DNS servers into their products so that they know their ads will get through even if you try to use something like PiHole.
I have used a decade of technical knowledge, money for an always on server, and countless hours of frustration and research to set this up: resources that I am privileged to have, and that not many people have the luxury of. But every day it becomes a little less effective and a little more exhausting, because I’m fighting a losing battle against teams fielded by multi-billion dollar corporations who are very much onto me.
And yes, I have Firefox. I have addons that block sponsored results on Amazon and remove all the “related” gunk from YouTube searches and let you hide results from SEO farm domains in DuckDuckGo (which is just a proxy for Bing; it doesn’t track you but it’s not like the results are anything special, and it’s not surprising it favors MSN results for news). I have Safari extensions that do a lot of this on my phone too. I do almost everything a reasonably busy adult can, and I STILL have a shitty internet experience because no matter how much time, money, and effort you put into this, you are fighting against the technical, legislative, and monopolistic efforts of massive companies designed specifically to ensure you fail.
Hell, I even went the complete other direction and went capitalist by paying for tumblr ad-free, and I STILL got that damn creepy clown and the sponsored dashboard tabs you couldn’t remove, because nothing I can give tumblr is any good compared to what Netflix can give them.
I’m so, so tired. Yes, use Firefox (on Android; on iOS don’t bother because Apple restricts the hell out of Firefox. Use Safari with these extensions, for starters). But don’t act like it’s a cure-all for an enshittified internet, because it very much is not.
In recent years, Google users have developed one very specific complaint about the ubiquitous search engine: They can’t find any answers. A simple search for “best pc for gaming” leads to a page dominated by sponsored links rather than helpful advice on which computer to buy. Meanwhile, the actual results are chock-full of low-quality, search-engine-optimized affiliate content designed to generate money for the publisher rather than provide high-quality answers. As a result, users have resorted to work-arounds and hacks to try and find useful information among the ads and low-quality chum. In short, Google’s flagship service now sucks.
And Google isn’t the only tech giant with a slowly deteriorating core product. Facebook, a website ostensibly for finding and connecting with your friends, constantly floods users’ feeds with sponsored (or “recommended”) content, and seems to bury the things people want to see under what Facebook decides is relevant. And as journalist John Herrman wrote earlier this year, the “junkification of Amazon” has made it nearly impossible for users to find a high-quality product they want — instead diverting people to ad-riddled result pages filled with low-quality products from sellers who know how to game the system.
All of these miserable online experiences are symptoms of an insidious underlying disease: In Silicon Valley, the user’s experience has become subordinate to the company’s stock price. Google, Amazon, Meta, and other tech companies have monetized confusion, constantly testing how much they can interfere with and manipulate users. And instead of trying to meaningfully innovate and improve the useful services they provide, these companies have instead chased short-term fads or attempted to totally overhaul their businesses in a desperate attempt to win the favor of Wall Street investors. As a result, our collective online experience is getting worse — it’s harder to buy the things you want to buy, more convoluted to search for info
#capitalism#internet privacy#firefox#enshittification#digital privacy#firefox extensions#adblockers#pihole#long post
31K notes
·
View notes
Text
New AMD ROCm 6.3 Release Expands AI and HPC Horizons

Opening Up New Paths in AI and HPC with AMD’s Release ROCm 6.3. With the introduction of cutting-edge tools and optimizations to improve AI, ML, and HPC workloads on AMD Instinct GPU accelerators, ROCm 6.3 represents a major milestone for the AMD open-source platform. By increasing developer productivity, ROCm 6.3 is designed to enable a diverse spectrum of clients, from cutting-edge AI startups to HPC-driven businesses.
This blog explores the release’s key features, which include a redesigned FlashAttention-2 for better AI training and inference, the introduction of multi-node Fast Fourier Transform (FFT) to transform HPC workflows, a smooth integration of SGLang for faster AI inferencing, and more. Discover these fascinating developments and more as ROCm 6.3 propels industry innovation.
Super-Fast Inferencing of Generative AI (GenAI) Models with SGLang in ROCm 6.3
Industries are being revolutionized by GenAI, yet implementing huge models frequently involves overcoming latency, throughput, and resource usage issues. Presenting SGLang, a new runtime optimized for inferring state-of-the-art generative models like LLMs and VLMs on AMD Instinct GPUs and supported by ROCm 6.3.
Why It Is Important to You
6X Higher Throughput: According to research, you can outperform current systems on LLM inferencing by up to 6X, allowing your company to support AI applications on a large scale.
Usability: With Python integrated and pre-configured in the ROCm Docker containers, developers can quickly construct scalable cloud backends, multimodal processes, and interactive AI helpers with less setup time.
SGLang provides the performance and usability required to satisfy corporate objectives, whether you’re developing AI products that interact with customers or expanding AI workloads in the cloud.
Next-Level Transformer Optimization: Re-Engineered FlashAttention-2 on AMD Instinct
The foundation of contemporary AI is transformer models, although scalability has always been constrained by their large memory and processing requirements. AMD resolves these issues with FlashAttention-2 designed for ROCm 6.3, allowing for quicker, more effective training and inference.
Why It Will Be Favorite by Developers
3X Speedups: In comparison to FlashAttention-1, achieve up to 3X speedups on backward passes and a highly efficient forward pass. This will speed up model training and inference, lowering the time-to-market for corporate AI applications.
Extended Sequence Lengths: AMD Instinct GPUs handle longer sequences with ease with to their effective memory use and low I/O overhead.
With ROCm’s PyTorch container and Composable Kernel (CK) as the backend, you can easily add FlashAttention-2 on AMD Instinct GPU accelerators into your current workflows and optimize your AI pipelines.
AMD Fortran Compiler: Bridging Legacy Code to GPU Acceleration
With the release of the new AMD Fortran compiler in ROCm 6.3, businesses using AMD Instinct accelerators to run historical Fortran-based HPC applications may now fully utilize the potential of contemporary GPU acceleration.
Principal Advantages
Direct GPU Offloading: Use OpenMP offloading to take advantage of AMD Instinct GPUs and speed up important scientific applications.
Backward Compatibility: Utilize AMD’s next-generation GPU capabilities while building upon pre-existing Fortran code.
Streamlined Integrations: Connect to ROCm Libraries and HIP Kernels with ease, removing the need for intricate code rewrites.
Businesses in sectors like weather modeling, pharmaceuticals, and aerospace may now leverage the potential of GPU acceleration without requiring the kind of substantial code overhauls that were previously necessary to future-proof their older HPC systems. This comprehensive tutorial will help you get started with the AMD Fortran Compiler on AMD Instinct GPUs.
New Multi-Node FFT in rocFFT: Game changer for HPC Workflows
Distributed computing systems that scale well are necessary for industries that depend on HPC workloads, such as oil and gas and climate modeling. High-performance distributed FFT calculations are made possible by ROCm 6.3, which adds multi-node FFT functionality to rocFFT.
The Significance of It for HPC
The integration of the built-in Message Passing Interface (MPI) streamlines multi-node scalability, lowering developer complexity and hastening the deployment of distributed applications.
Scalability of Leadership: Optimize performance for crucial activities like climate modeling and seismic imaging by scaling fluidly over large datasets.
Larger datasets may now be processed more efficiently by organizations in sectors like scientific research and oil and gas, resulting in quicker and more accurate decision-making.
Enhanced Computer Vision Libraries: AV1, rocJPEG, and Beyond
AI developers need effective preprocessing and augmentation tools when dealing with contemporary media and datasets. With improvements to its computer vision libraries, rocDecode, rocJPEG, and rocAL, ROCm 6.3 enables businesses to take on a variety of tasks, from dataset augmentation to video analytics.
Why It Is Important to You
Support for the AV1 Codec: rocDecode and rocPyDecode provide affordable, royalty-free decoding for contemporary media processing.
GPU-Accelerated JPEG Decoding: Use the rocJPEG library’s built-in fallback methods to perform image preparation at scale with ease.
Better Audio Augmentation: Using the rocAL package, preprocessing has been enhanced for reliable model training in noisy situations.
From entertainment and media to self-governing systems, these characteristics allow engineers to produce more complex AI solutions for practical uses.
It’s important to note that, in addition to these noteworthy improvements, Omnitrace and Omniperf which were first released in ROCm 6.2 have been renamed as ROCm System Profiler and ROCm Compute Profiler. Improved usability, reliability, and smooth integration into the existing ROCm profiling environment are all benefits of this rebranding.
Why ROCm 6.3?
AMD With each release, ROCm has advanced, and version 6.3 is no different. It offers state-of-the-art tools to streamline development and improve speed and scalability for workloads including AI and HPC. ROCm enables companies to innovate more quickly, grow more intelligently, and maintain an advantage in cutthroat markets by adopting the open-source philosophy and constantly changing to satisfy developer demands.
Are You Prepared to Jump? Examine ROCm 6.3‘s full potential and discover how AMD Instinct accelerators may support the next significant innovation in your company.
Read more on Govindhtech.com
#AMDROCm6.3#ROCm6.3#AMDROCm#AI#HPC#AMDInstinctGPU#AMDInstinct#GPUAcceleration#News#Technews#Technology#Technologynews#Technologytrends#Govindhtech
0 notes
Text
Kill Containers and remove unused images from Docker Correctly
In this article, we shall discuss how to destroy, that is “Kill Containers and remove unused images from Docker Correctly”. We will be doing this over Portainer and Container Manager. Containers and images that are no longer in use can create clutter, making it harder to manage Docker environments. By removing them, you can streamline the system, keeping only essential resources running. Please…
#container lifecycle#container management#Container Manager#delete images#Docker best practices#Docker cleanup#docker cli#Docker commands#Docker maintenance#Docker system prune#efficient Docker management#Exited Code 137#image management#kill containers#portainer#remove unused images#resource optimization#stop containers#system resources
0 notes
Text
Deploying Large Language Models on Kubernetes: A Comprehensive Guide
New Post has been published on https://thedigitalinsider.com/deploying-large-language-models-on-kubernetes-a-comprehensive-guide/
Deploying Large Language Models on Kubernetes: A Comprehensive Guide
Large Language Models (LLMs) are capable of understanding and generating human-like text, making them invaluable for a wide range of applications, such as chatbots, content generation, and language translation.
However, deploying LLMs can be a challenging task due to their immense size and computational requirements. Kubernetes, an open-source container orchestration system, provides a powerful solution for deploying and managing LLMs at scale. In this technical blog, we’ll explore the process of deploying LLMs on Kubernetes, covering various aspects such as containerization, resource allocation, and scalability.
Understanding Large Language Models
Before diving into the deployment process, let’s briefly understand what Large Language Models are and why they are gaining so much attention.
Large Language Models (LLMs) are a type of neural network model trained on vast amounts of text data. These models learn to understand and generate human-like language by analyzing patterns and relationships within the training data. Some popular examples of LLMs include GPT (Generative Pre-trained Transformer), BERT (Bidirectional Encoder Representations from Transformers), and XLNet.
LLMs have achieved remarkable performance in various NLP tasks, such as text generation, language translation, and question answering. However, their massive size and computational requirements pose significant challenges for deployment and inference.
Why Kubernetes for LLM Deployment?
Kubernetes is an open-source container orchestration platform that automates the deployment, scaling, and management of containerized applications. It provides several benefits for deploying LLMs, including:
Scalability: Kubernetes allows you to scale your LLM deployment horizontally by adding or removing compute resources as needed, ensuring optimal resource utilization and performance.
Resource Management: Kubernetes enables efficient resource allocation and isolation, ensuring that your LLM deployment has access to the required compute, memory, and GPU resources.
High Availability: Kubernetes provides built-in mechanisms for self-healing, automatic rollouts, and rollbacks, ensuring that your LLM deployment remains highly available and resilient to failures.
Portability: Containerized LLM deployments can be easily moved between different environments, such as on-premises data centers or cloud platforms, without the need for extensive reconfiguration.
Ecosystem and Community Support: Kubernetes has a large and active community, providing a wealth of tools, libraries, and resources for deploying and managing complex applications like LLMs.
Preparing for LLM Deployment on Kubernetes:
Before deploying an LLM on Kubernetes, there are several prerequisites to consider:
Kubernetes Cluster: You’ll need a Kubernetes cluster set up and running, either on-premises or on a cloud platform like Amazon Elastic Kubernetes Service (EKS), Google Kubernetes Engine (GKE), or Azure Kubernetes Service (AKS).
GPU Support: LLMs are computationally intensive and often require GPU acceleration for efficient inference. Ensure that your Kubernetes cluster has access to GPU resources, either through physical GPUs or cloud-based GPU instances.
Container Registry: You’ll need a container registry to store your LLM Docker images. Popular options include Docker Hub, Amazon Elastic Container Registry (ECR), Google Container Registry (GCR), or Azure Container Registry (ACR).
LLM Model Files: Obtain the pre-trained LLM model files (weights, configuration, and tokenizer) from the respective source or train your own model.
Containerization: Containerize your LLM application using Docker or a similar container runtime. This involves creating a Dockerfile that packages your LLM code, dependencies, and model files into a Docker image.
Deploying an LLM on Kubernetes
Once you have the prerequisites in place, you can proceed with deploying your LLM on Kubernetes. The deployment process typically involves the following steps:
Building the Docker Image
Build the Docker image for your LLM application using the provided Dockerfile and push it to your container registry.
Creating Kubernetes Resources
Define the Kubernetes resources required for your LLM deployment, such as Deployments, Services, ConfigMaps, and Secrets. These resources are typically defined using YAML or JSON manifests.
Configuring Resource Requirements
Specify the resource requirements for your LLM deployment, including CPU, memory, and GPU resources. This ensures that your deployment has access to the necessary compute resources for efficient inference.
Deploying to Kubernetes
Use the kubectl command-line tool or a Kubernetes management tool (e.g., Kubernetes Dashboard, Rancher, or Lens) to apply the Kubernetes manifests and deploy your LLM application.
Monitoring and Scaling
Monitor the performance and resource utilization of your LLM deployment using Kubernetes monitoring tools like Prometheus and Grafana. Adjust the resource allocation or scale your deployment as needed to meet the demand.
Example Deployment
Let’s consider an example of deploying the GPT-3 language model on Kubernetes using a pre-built Docker image from Hugging Face. We’ll assume that you have a Kubernetes cluster set up and configured with GPU support.
Pull the Docker Image:
bashCopydocker pull huggingface/text-generation-inference:1.1.0
Create a Kubernetes Deployment:
Create a file named gpt3-deployment.yaml with the following content:
apiVersion: apps/v1 kind: Deployment metadata: name: gpt3-deployment spec: replicas: 1 selector: matchLabels: app: gpt3 template: metadata: labels: app: gpt3 spec: containers: - name: gpt3 image: huggingface/text-generation-inference:1.1.0 resources: limits: nvidia.com/gpu: 1 env: - name: MODEL_ID value: gpt2 - name: NUM_SHARD value: "1" - name: PORT value: "8080" - name: QUANTIZE value: bitsandbytes-nf4
This deployment specifies that we want to run one replica of the gpt3 container using the huggingface/text-generation-inference:1.1.0 Docker image. The deployment also sets the environment variables required for the container to load the GPT-3 model and configure the inference server.
Create a Kubernetes Service:
Create a file named gpt3-service.yaml with the following content:
apiVersion: v1 kind: Service metadata: name: gpt3-service spec: selector: app: gpt3 ports: - port: 80 targetPort: 8080 type: LoadBalancer
This service exposes the gpt3 deployment on port 80 and creates a LoadBalancer type service to make the inference server accessible from outside the Kubernetes cluster.
Deploy to Kubernetes:
Apply the Kubernetes manifests using the kubectl command:
kubectl apply -f gpt3-deployment.yaml kubectl apply -f gpt3-service.yaml
Monitor the Deployment:
Monitor the deployment progress using the following commands:
kubectl get pods kubectl logs <pod_name>
Once the pod is running and the logs indicate that the model is loaded and ready, you can obtain the external IP address of the LoadBalancer service:
kubectl get service gpt3-service
Test the Deployment:
You can now send requests to the inference server using the external IP address and port obtained from the previous step. For example, using curl:
curl -X POST http://<external_ip>:80/generate -H 'Content-Type: application/json' -d '"inputs": "The quick brown fox", "parameters": "max_new_tokens": 50'
This command sends a text generation request to the GPT-3 inference server, asking it to continue the prompt “The quick brown fox” for up to 50 additional tokens.
Advanced topics you should be aware of
While the example above demonstrates a basic deployment of an LLM on Kubernetes, there are several advanced topics and considerations to explore:
_*]:min-w-0″ readability=”131.72387362124″>
1. Autoscaling
Kubernetes supports horizontal and vertical autoscaling, which can be beneficial for LLM deployments due to their variable computational demands. Horizontal autoscaling allows you to automatically scale the number of replicas (pods) based on metrics like CPU or memory utilization. Vertical autoscaling, on the other hand, allows you to dynamically adjust the resource requests and limits for your containers.
To enable autoscaling, you can use the Kubernetes Horizontal Pod Autoscaler (HPA) and Vertical Pod Autoscaler (VPA). These components monitor your deployment and automatically scale resources based on predefined rules and thresholds.
2. GPU Scheduling and Sharing
In scenarios where multiple LLM deployments or other GPU-intensive workloads are running on the same Kubernetes cluster, efficient GPU scheduling and sharing become crucial. Kubernetes provides several mechanisms to ensure fair and efficient GPU utilization, such as GPU device plugins, node selectors, and resource limits.
You can also leverage advanced GPU scheduling techniques like NVIDIA Multi-Instance GPU (MIG) or AMD Memory Pool Remapping (MPR) to virtualize GPUs and share them among multiple workloads.
3. Model Parallelism and Sharding
Some LLMs, particularly those with billions or trillions of parameters, may not fit entirely into the memory of a single GPU or even a single node. In such cases, you can employ model parallelism and sharding techniques to distribute the model across multiple GPUs or nodes.
Model parallelism involves splitting the model architecture into different components (e.g., encoder, decoder) and distributing them across multiple devices. Sharding, on the other hand, involves partitioning the model parameters and distributing them across multiple devices or nodes.
Kubernetes provides mechanisms like StatefulSets and Custom Resource Definitions (CRDs) to manage and orchestrate distributed LLM deployments with model parallelism and sharding.
4. Fine-tuning and Continuous Learning
In many cases, pre-trained LLMs may need to be fine-tuned or continuously trained on domain-specific data to improve their performance for specific tasks or domains. Kubernetes can facilitate this process by providing a scalable and resilient platform for running fine-tuning or continuous learning workloads.
You can leverage Kubernetes batch processing frameworks like Apache Spark or Kubeflow to run distributed fine-tuning or training jobs on your LLM models. Additionally, you can integrate your fine-tuned or continuously trained models with your inference deployments using Kubernetes mechanisms like rolling updates or blue/green deployments.
5. Monitoring and Observability
Monitoring and observability are crucial aspects of any production deployment, including LLM deployments on Kubernetes. Kubernetes provides built-in monitoring solutions like Prometheus and integrations with popular observability platforms like Grafana, Elasticsearch, and Jaeger.
You can monitor various metrics related to your LLM deployments, such as CPU and memory utilization, GPU usage, inference latency, and throughput. Additionally, you can collect and analyze application-level logs and traces to gain insights into the behavior and performance of your LLM models.
6. Security and Compliance
Depending on your use case and the sensitivity of the data involved, you may need to consider security and compliance aspects when deploying LLMs on Kubernetes. Kubernetes provides several features and integrations to enhance security, such as network policies, role-based access control (RBAC), secrets management, and integration with external security solutions like HashiCorp Vault or AWS Secrets Manager.
Additionally, if you’re deploying LLMs in regulated industries or handling sensitive data, you may need to ensure compliance with relevant standards and regulations, such as GDPR, HIPAA, or PCI-DSS.
7. Multi-Cloud and Hybrid Deployments
While this blog post focuses on deploying LLMs on a single Kubernetes cluster, you may need to consider multi-cloud or hybrid deployments in some scenarios. Kubernetes provides a consistent platform for deploying and managing applications across different cloud providers and on-premises data centers.
You can leverage Kubernetes federation or multi-cluster management tools like KubeFed or GKE Hub to manage and orchestrate LLM deployments across multiple Kubernetes clusters spanning different cloud providers or hybrid environments.
These advanced topics highlight the flexibility and scalability of Kubernetes for deploying and managing LLMs.
Conclusion
Deploying Large Language Models (LLMs) on Kubernetes offers numerous benefits, including scalability, resource management, high availability, and portability. By following the steps outlined in this technical blog, you can containerize your LLM application, define the necessary Kubernetes resources, and deploy it to a Kubernetes cluster.
However, deploying LLMs on Kubernetes is just the first step. As your application grows and your requirements evolve, you may need to explore advanced topics such as autoscaling, GPU scheduling, model parallelism, fine-tuning, monitoring, security, and multi-cloud deployments.
Kubernetes provides a robust and extensible platform for deploying and managing LLMs, enabling you to build reliable, scalable, and secure applications.
#access control#Amazon#Amazon Elastic Kubernetes Service#amd#Apache#Apache Spark#app#applications#apps#architecture#Artificial Intelligence#attention#AWS#azure#Behavior#BERT#Blog#Blue#Building#chatbots#Cloud#cloud platform#cloud providers#cluster#clusters#code#command#Community#compliance#comprehensive
0 notes
Text
Unleashing Potential: Scalability and Flexibility in SAP Carve-Out Architectures

In the realm of SAP carve-out initiatives, the architecture plays a pivotal role in determining the scalability and flexibility of the transition process. As organizations embark on carve-out projects to separate specific business units or processes from their parent SAP environment, they must design architectures that can adapt to evolving business requirements, accommodate growth, and facilitate seamless integration with existing systems. Scalability and flexibility are not just desirable traits but critical enablers of success in SAP carve-outs, allowing organizations to navigate complexities and capitalize on new opportunities effectively.
Designing Modular Architectures
A key strategy for achieving scalability and flexibility in SAP carve-out architectures is the adoption of modular design principles. By breaking down the SAP landscape into modular components or building blocks, organizations can create flexible architectures that can be easily scaled up or down to meet changing business needs. Modular architectures enable organizations to add or remove components as required, facilitating incremental growth and adaptation without disrupting the entire system. Additionally, modular design simplifies maintenance and upgrades, allowing organizations to implement changes efficiently and cost-effectively.
Leveraging Cloud Technologies
Cloud technologies offer unparalleled scalability and flexibility for SAP carve-out architectures, providing organizations with on-demand access to computing resources and services. By migrating SAP environments to the cloud, organizations can leverage scalable infrastructure and platform solutions that can adapt to fluctuating workloads and evolving business requirements. Cloud-based architectures enable organizations to scale resources dynamically, optimize performance, and achieve greater agility in responding to changing market conditions. Additionally, cloud platforms offer built-in redundancy, disaster recovery capabilities, and security features, enhancing the resilience and reliability of SAP carve-out environments.
Embracing Microservices Architecture
Microservices architecture represents a paradigm shift in SAP carve-out architectures, offering granular scalability and flexibility by decomposing monolithic SAP applications into independently deployable services. By decoupling functionalities and adopting a service-oriented approach, organizations can design highly scalable and flexible architectures that can evolve independently, enabling rapid innovation and experimentation. Microservices architectures facilitate seamless integration with third-party systems, support agile development methodologies, and promote cross-functional collaboration, empowering organizations to deliver value more efficiently and respond to market changes with agility.
Implementing Containerization Technologies
Containerization technologies such as Docker and Kubernetes are revolutionizing SAP carve-out architectures, providing lightweight, portable, and scalable runtime environments for SAP applications. By encapsulating SAP components and dependencies into containers, organizations can achieve greater scalability and flexibility while simplifying deployment, management, and scaling operations. Containerization enables organizations to deploy SAP applications consistently across different environments, including on-premises data centers, public clouds, and hybrid infrastructures, ensuring portability and interoperability. Additionally, container orchestration platforms like Kubernetes automate scaling, load balancing, and resource allocation, enabling organizations to optimize performance and cost-effectiveness in SAP carve-out environments.
Conclusion
In conclusion, scalability and flexibility are paramount considerations in designing SAP carve-out architectures, allowing organizations to adapt to changing business needs, accommodate growth, and capitalize on new opportunities effectively. By embracing modular design principles, leveraging cloud technologies, embracing microservices architecture, and implementing containerization technologies, organizations can create agile, resilient, and future-proof SAP carve-out architectures that enable them to thrive in a dynamic business landscape. With scalable and flexible architectures in place, organizations can accelerate innovation, drive digital transformation, and achieve sustainable growth in their carve-out initiatives.
1 note
·
View note
Text
How to make Selenium testing more efficient with Docker

The reliability and compatibility of web applications across different environments are crucial. Docker, a popular containerization platform, offers a streamlined way to achieve this by providing a consistent testing environment.
In 2022, Docker accounted for 27 percent market share of the containerization technologies market. – Statista
What is Docker?
Docker is an open-source platform that automates the deployment of applications in lightweight portable containers. These containers package applications and their dependencies together, ensuring consistency across different environments.
Why to use Docker for Selenium testing
Isolation: Each test runs in a separate container, preventing interference between tests.
Consistency: The testing environment is consistent across different machines and environments.
Efficiency: Tests can be parallelized easily using Docker, reducing execution time.
Scalability: Docker allows you to scale up your testing infrastructure effortlessly.
Using Docker for application compatibility
You need to ensure that your application is compatible with different browsers (e.g., Chrome, Firefox) and different versions of those browsers. Additionally, as your application’s functionality grows, multiple tests need to be run concurrently to maintain efficiency.
Benefits of leveraging Docker
Regression testing: It is a process of testing your application to ensure that it still works correctly after changes have been made to it. By using Docker, you can create a consistent environment for regression testing, which can help you identify and fix bugs more quickly.
Parallel test execution: Docker can help you run multiple tests in parallel, which can significantly reduce the time it takes to execute all your tests. This is especially beneficial for large test suites that can take a long time to execute.
Consistent environment: Docker creates isolated environments for each test, which ensures that each test runs in a clean environment that is free of any dependencies or configurations from other tests. This can help prevent test failures caused by environmental factors.
Scalability: You can easily add or remove containers as needed. This can be helpful if you need to increase the number of tests that you are running or if you need to test on many browsers or devices.
Reduced test execution time: Docker can help reduce the time it takes to execute tests by sharing resources between containers and caching dependencies. This can be a significant benefit for large test suites that can take a long time to execute.
Setting up your environment with Docker
– Installing Docker
To get started, install Docker on your machine by following the instructions on the official Docker website (https://www.Docker.com/).
– Creating a Selenium Test Suite
Develop a Selenium test suite using your preferred programming language (Java, Python, etc.) and testing framework (JUnit, TestNG, etc.). Ensure your tests are organized and ready for execution.
-Configure Docker Compose file
Docker Compose is a tool for defining and running multi-container Docker applications. Create a Docker Compose YML file to configure your container and any other services like Selenium Grid and web browsers like Firefox, Chrome, etc.
– Example of Docker-compose.yml
version: “3” services: Chrome: image: selenium/node-chrome:latest shm_size: 2gb depends_on: – selenium-hub environment: – SE_EVENT_BUS_HOST=selenium-hub – SE_EVENT_BUS_PUBLISH_PORT=4442 – SE_EVENT_BUS_SUBSCRIBE_PORT=4443
Firefox: image: selenium/node-firefox:latest shm_size: 2gb depends_on: – selenium-hub environment: – SE_EVENT_BUS_HOST=selenium-hub – SE_EVENT_BUS_PUBLISH_PORT=4442 – SE_EVENT_BUS_SUBSCRIBE_PORT=4443
Selenium-hub: image: selenium/hub:latest container_name: selenium-hub ports: – “4442:4442” – “4443:4443” – “4444:4444”
You can expand upon this file to include more browser nodes or additional services as needed. Each browser node service should link to the Selenium-hub service to establish communication.
Navigate to the directory containing the compose file and run the “Docker compose -f Docker-compose.yml up” command.
This will start the Selenium hub and the specified browser nodes. You can then configure your Selenium test suite to connect to the Selenium hub at the specified URL http://localhost:4444 and distribute the tests among the available browser nodes.
– Configure Selenium code for execution in the remote web driver DesiredCapabilities chromeCapabilities = DesiredCapabilities.chrome(); // Set any desired capabilities here URL hubUrl = new URL("http://<selenium-hub ip>:4444/wd/hub"); // URL of the Selenium Grid prepared in container. If you have set up Docker in local, then the Selenium hub URL will be http://localhost:4444. WebDriver driver = new RemoteWebDriver(hubUrl, chromeCapabilities ); Copy
– Execute the test
When you run your tests, Selenium will route the commands to the appropriate browser node based on the desired capabilities. The tests will be executed in Docker containers.
Offer better quality software products with QA automation
Docker provides an effective solution for executing Selenium tests in a controlled and reproducible environment. By containerizing your tests, you can achieve consistency, efficiency, and scalability in your testing processes. Ensure the quality of your web applications by integrating Docker into your testing workflow.
Softweb Solutions is one of the leading providers of QA automation services. We automate testing processes to improve quality, efficiency, and scalability for businesses of all sizes. We have a team of experienced QA engineers who are experts in Docker and Selenium. We can help you set up a Docker-based Selenium environment and automate your tests. We also offer training and support to help you get the most out of Docker for Selenium testing.
Originally published at www.softwebsolutions.com on September 1st, 2023.
#QA automation services#Benefits of Test Automation#automation testing services#test automation services#qa automation
0 notes
Text
Docker Architecture

Docker is a popular platform that allows developers to create, deploy, and run applications inside containers. Containers are lightweight, portable, and isolated environments that package an application and all its dependencies, making it easy to run consistently across different environments. Docker's architecture consists of several components that work together to manage containers efficiently. Here's an overview of the Docker architecture:
Docker Engine: At the core of Docker's architecture is the Docker Engine, which is responsible for building, running, and managing containers. It consists of two main components:
Docker Daemon: The Docker daemon (dockerd) is a background service that runs on the host machine. It handles container operations, such as creating, starting, stopping, and deleting containers. The Docker daemon listens for API requests and manages the container lifecycle.
Docker CLI: The Docker Command-Line Interface (CLI) is a client tool that allows users to interact with the Docker daemon. Developers use the Docker CLI to issue commands to manage containers, images, networks, and other Docker-related resources.
Container: A container is an instance of an image that is running as a process on the host machine. It contains the application code, runtime, system libraries, and other dependencies required to run the application. Containers are isolated from each other and the host system, ensuring that the application runs consistently regardless of the environment.
Docker Images: A Docker image is a read-only template used to create containers. It includes the application code, runtime, libraries, environment variables, and other necessary components. Images are built from a set of instructions defined in a Dockerfile, which is a text file that specifies how to assemble the image.
Docker Registry: A Docker registry is a repository that stores Docker images. Docker Hub is the default public registry provided by Docker, but organizations often use private registries to store their custom-built images securely.
Docker Compose: Docker Compose is a tool for defining and running multi-container Docker applications. It uses a YAML file to configure the services, networks, and volumes required for the application. With Docker Compose, you can define complex applications with multiple interconnected containers and manage them as a single unit.
Docker Network: Docker provides a networking capability that allows containers to communicate with each other and the external world. Docker creates a bridge network by default and allows you to create custom networks to isolate containers or facilitate communication between specific containers.
Docker Volumes: Docker volumes are used to persist data beyond the lifecycle of a container. They provide a way to share data between containers and store data that should persist even if the container is removed or replaced.
The Docker architecture is designed to be scalable, allowing developers to run containers on a single development machine or distribute applications across a cluster of servers. With Docker's flexibility and ease of use, it has become a valuable tool for modern software development and deployment, especially in the context of microservices, continuous integration, and continuous delivery workflows.
Visit our website for more-https://www.doremonlabs.com/
0 notes
Text
Purge or clean all the resources from Docker
Clean up any resources from the Docker Pruge or clear all the resources like networks, images, volumes, and containers which are not linked with any container # docker system prune Remove stopped containers and all unused images by using -a # docker system prune -a Remove specific images: --List the images # docker images -a --Remove specific images #docker rmi <imageid> -- Note: if you…
View On WordPress
0 notes
Text
Implementing SOPs for WordPress: Choose a Stack and Stick With It!
Stack standardization allows WordPress professionals to streamline development.
Stack standardization allows WordPress professionals to streamline development. Use our SOP for Setting Up A Beaver Builder Website Using Astra theme And Ultimate Addons For Beaver Builder
Click here to Download PDF
Who is it for: Who is it for: WordPress team, WordPress management team, QA team
Outcomes:
It will help in following coding standards for the Beaver Builder website.
Helps in managing and updating Beaver builder sites easily.
Easy for the team to identify the work of other team members and find the files easily to update.
Helpful for new employees and trainees.
Critical Steps:
Always confirm with the manager whether to use a paid or free version of the Beaver Builder plugin, Ultimate addons for Beaver builder plugin, and Astra theme.
When using the free version of Beaver Builder and Ultimate Addons, make sure 80% of the design is achievable through the free version. If not, consult with your team lead or manager and request for a paid version or other alternatives if possible.
Install and activate plugins (Beaver Builder, Ultimate Addons). Pro versions of plugins will be provided by your team lead or manager. Free versions of the plugins should be removed and deleted from the site if you are using the Pro versions of the plugins. Also, use the Beaver themer plugin if the site would have a post archive and single pages. For the Beaver Themer plugin, Beaver builder PRO is mandatory.
Click here to Download PDF
Every one of your client’s sites is unique.
Part of your job as a WordPress developer is finding out what makes your client’s project special and leveraging that special characteristic to generate value.
But just because a website’s core value is unique does not mean that the technology behind it has to be. There’s no need to reinvent the wheel with every new project you take on.
Over the last couple of months, we’ve covered a variety of benefits and use cases associated with standard operating procedures (SOPs), and even given away free templates to help digital agencies make their own. Now we’re going to talk about how standardization can create competitive advantages in our industry.
One of the main places where having a core set of operating standards helps most is when you’re choosing your preferred WordPress software stack.
Choose a Versatile WordPress Stack
As a developer, it should be plainly evident that your choice of software stack impacts your ability to respond to client needs with accuracy and agility. The broader and more diverse your clients’ needs are, the more versatile your stack of themes, plugins, and other tools will need to be.
This is one of the reasons why it’s important to build a niche for yourself as soon as possible. Having clients that are similar to one another in terms of their technology requirements helps you choose tools that best resolve their most common problems. As an added bonus, it consolidates your industry reputation for solving those types of problems.
This is especially true if you want your agency to operate as a “web development agency”. If you want to handle client-side, server-side, front-end, and back-end problems for your clients in a comprehensive way, you will need to choose a technology stack that is both versatile and powerful.
WordPress itself is a PHP application, which means you’re going to need to find ways to optimize your ability to compile and run PHP applications. You may even wish to include a tool like Docker or Laravel into your workflow.
Laravel is particularly useful because it allows you to maintain and scale PHP applications easily over time. Development frameworks are hugely popular because they directly address the “reinventing the wheel” problem that developers often face when dealing with multiple clients over time.
Diving Deeper Into WordPress: Choosing Themes and Plugins for Your Stack
As a WordPress agency, your development stack goes further than PHP development frameworks. You are virtually guaranteed to use, create, or modify WordPress themes and plugins in the course of your daily work.
If you do not take the time to establish a comprehensive set of first-priority themes and plugins to use, you run the risk of over-extending your agency’s technology needs in a way that is difficult to scale.
Remember that every theme and plugin you decide to use also comes with maintenance and update requirements. If you pick a brand-new set of WordPress themes and plugins for every customer you have, you will quickly find yourself spending more time updating and maintaining all of those technologies that you spend actually generating value for your customers.
On the other hand, if you stick to a relatively small number of themes and plugins that you repeatedly use for multiple customers, you will save an enormous amount of time on maintenance over time. This will help you earn greater profits from your retainer agreements and improve your quality of life immensely.
Use our SOP for Setting Up A Beaver Builder Website Using Astra theme And Ultimate Addons For Beaver Builder
Click here to Download PDF
Who is it for: Who is it for: WordPress team, WordPress management team, QA team
Outcomes:
It will help in following coding standards for the Beaver Builder website.
Helps in managing and updating Beaver builder sites easily.
Easy for the team to identify the work of other team members and find the files easily to update.
Helpful for new employees and trainees.
Critical Steps:
Always confirm with the manager whether to use a paid or free version of the Beaver Builder plugin, Ultimate addons for Beaver builder plugin, and Astra theme.
When using the free version of Beaver Builder and Ultimate Addons, make sure 80% of the design is achievable through the free version. If not, consult with your team lead or manager and request for a paid version or other alternatives if possible.
Install and activate plugins (Beaver Builder, Ultimate Addons). Pro versions of plugins will be provided by your team lead or manager. Free versions of the plugins should be removed and deleted from the site if you are using the Pro versions of the plugins. Also, use the Beaver themer plugin if the site would have a post archive and single pages. For the Beaver Themer plugin, Beaver builder PRO is mandatory.
Click here to Download PDF
How SOPs Help Standardize Technology Stacks: An Example
At UnlimitedWP we use the Beaver Builder plugin, Ultimate Addons for Beaver Builder plugin, and the Astra theme on the majority of the websites we build.
Since we have experience with these technologies already, we are able to complete tasks that rely on them faster and more efficiently. If we used a constantly changing menu of builders and themes, we would have to dedicate time to learn how each one works at a deep level, and then spend even more time maintaining and updating them for our partners.
Since this particular stack of technologies is sufficient to set up a default website in almost all of our development scenarios, it makes sense to standardize the way we use it. This is where our website setup SOP takes a central role.
The SOP is designed so that any member of our team has all the information and resources needed to create a default WordPress template using the Beaver Builder plugin, the Ultimate Addons for Beaver Builder plugin, and the Astra theme. The finished output is ready to move onto the next part of our workflow – customization, and development.
Our white label WordPress agency’s whole value proposition relies on being able to offer unlimited WordPress tasks to agencies at a single monthly rate. We have to optimize every step of the development process in order to generate value for agencies who want to outsource WordPress tasks to our team, and standardization is a key part of that.
Standardization Helps Scalability
If you run an agency where one or two people handle almost all client requests, you may believe that there is no urgent need to create standard operating procedures. After all, you can keep track of the way you configure your technology stack to meet your clients’ needs.
However, this changes radically once your agency starts growing. If you need to offload some of your projects on a newly hired developer (or a white label partner agency), you will suddenly be faced with a dilemma. The new developer may have different configuration priorities than you do. They may operate on different assumptions or use a different set of tools to arrive at the desired outcome.
If you don’t carefully assess the way you delegate tasks to your team members and third-party service providers, you can actually become an obstacle to your own agency’s growth. Standardization means that any employee can reliably complete a given task without needing additional training beyond the established operating procedures.
In terms of overall productivity, the net gain expands at an exponential rate as your company grows. Standardization is one of the fundamental keys to achieving that kind of growth.
#wordpress development#wordpress care packages#wordpress development support#wordpress website development#wordpress website services
2 notes
·
View notes
Text
How to set up command-line access to Amazon Keyspaces (for Apache Cassandra) by using the new developer toolkit Docker image
Amazon Keyspaces (for Apache Cassandra) is a scalable, highly available, and fully managed Cassandra-compatible database service. Amazon Keyspaces helps you run your Cassandra workloads more easily by using a serverless database that can scale up and down automatically in response to your actual application traffic. Because Amazon Keyspaces is serverless, there are no clusters or nodes to provision and manage. You can get started with Amazon Keyspaces with a few clicks in the console or a few changes to your existing Cassandra driver configuration. In this post, I show you how to set up command-line access to Amazon Keyspaces by using the keyspaces-toolkit Docker image. The keyspaces-toolkit Docker image contains commonly used Cassandra developer tooling. The toolkit comes with the Cassandra Query Language Shell (cqlsh) and is configured with best practices for Amazon Keyspaces. The container image is open source and also compatible with Apache Cassandra 3.x clusters. A command line interface (CLI) such as cqlsh can be useful when automating database activities. You can use cqlsh to run one-time queries and perform administrative tasks, such as modifying schemas or bulk-loading flat files. You also can use cqlsh to enable Amazon Keyspaces features, such as point-in-time recovery (PITR) backups and assign resource tags to keyspaces and tables. The following screenshot shows a cqlsh session connected to Amazon Keyspaces and the code to run a CQL create table statement. Build a Docker image To get started, download and build the Docker image so that you can run the keyspaces-toolkit in a container. A Docker image is the template for the complete and executable version of an application. It’s a way to package applications and preconfigured tools with all their dependencies. To build and run the image for this post, install the latest Docker engine and Git on the host or local environment. The following command builds the image from the source. docker build --tag amazon/keyspaces-toolkit --build-arg CLI_VERSION=latest https://github.com/aws-samples/amazon-keyspaces-toolkit.git The preceding command includes the following parameters: –tag – The name of the image in the name:tag Leaving out the tag results in latest. –build-arg CLI_VERSION – This allows you to specify the version of the base container. Docker images are composed of layers. If you’re using the AWS CLI Docker image, aligning versions significantly reduces the size and build times of the keyspaces-toolkit image. Connect to Amazon Keyspaces Now that you have a container image built and available in your local repository, you can use it to connect to Amazon Keyspaces. To use cqlsh with Amazon Keyspaces, create service-specific credentials for an existing AWS Identity and Access Management (IAM) user. The service-specific credentials enable IAM users to access Amazon Keyspaces, but not access other AWS services. The following command starts a new container running the cqlsh process. docker run --rm -ti amazon/keyspaces-toolkit cassandra.us-east-1.amazonaws.com 9142 --ssl -u "SERVICEUSERNAME" -p "SERVICEPASSWORD" The preceding command includes the following parameters: run – The Docker command to start the container from an image. It’s the equivalent to running create and start. –rm –Automatically removes the container when it exits and creates a container per session or run. -ti – Allocates a pseudo TTY (t) and keeps STDIN open (i) even if not attached (remove i when user input is not required). amazon/keyspaces-toolkit – The image name of the keyspaces-toolkit. us-east-1.amazonaws.com – The Amazon Keyspaces endpoint. 9142 – The default SSL port for Amazon Keyspaces. After connecting to Amazon Keyspaces, exit the cqlsh session and terminate the process by using the QUIT or EXIT command. Drop-in replacement Now, simplify the setup by assigning an alias (or DOSKEY for Windows) to the Docker command. The alias acts as a shortcut, enabling you to use the alias keyword instead of typing the entire command. You will use cqlsh as the alias keyword so that you can use the alias as a drop-in replacement for your existing Cassandra scripts. The alias contains the parameter –v "$(pwd)":/source, which mounts the current directory of the host. This is useful for importing and exporting data with COPY or using the cqlsh --file command to load external cqlsh scripts. alias cqlsh='docker run --rm -ti -v "$(pwd)":/source amazon/keyspaces-toolkit cassandra.us-east-1.amazonaws.com 9142 --ssl' For security reasons, don’t store the user name and password in the alias. After setting up the alias, you can create a new cqlsh session with Amazon Keyspaces by calling the alias and passing in the service-specific credentials. cqlsh -u "SERVICEUSERNAME" -p "SERVICEPASSWORD" Later in this post, I show how to use AWS Secrets Manager to avoid using plaintext credentials with cqlsh. You can use Secrets Manager to store, manage, and retrieve secrets. Create a keyspace Now that you have the container and alias set up, you can use the keyspaces-toolkit to create a keyspace by using cqlsh to run CQL statements. In Cassandra, a keyspace is the highest-order structure in the CQL schema, which represents a grouping of tables. A keyspace is commonly used to define the domain of a microservice or isolate clients in a multi-tenant strategy. Amazon Keyspaces is serverless, so you don’t have to configure clusters, hosts, or Java virtual machines to create a keyspace or table. When you create a new keyspace or table, it is associated with an AWS Account and Region. Though a traditional Cassandra cluster is limited to 200 to 500 tables, with Amazon Keyspaces the number of keyspaces and tables for an account and Region is virtually unlimited. The following command creates a new keyspace by using SingleRegionStrategy, which replicates data three times across multiple Availability Zones in a single AWS Region. Storage is billed by the raw size of a single replica, and there is no network transfer cost when replicating data across Availability Zones. Using keyspaces-toolkit, connect to Amazon Keyspaces and run the following command from within the cqlsh session. CREATE KEYSPACE amazon WITH REPLICATION = {'class': 'SingleRegionStrategy'} AND TAGS = {'domain' : 'shoppingcart' , 'app' : 'acme-commerce'}; The preceding command includes the following parameters: REPLICATION – SingleRegionStrategy replicates data three times across multiple Availability Zones. TAGS – A label that you assign to an AWS resource. For more information about using tags for access control, microservices, cost allocation, and risk management, see Tagging Best Practices. Create a table Previously, you created a keyspace without needing to define clusters or infrastructure. Now, you will add a table to your keyspace in a similar way. A Cassandra table definition looks like a traditional SQL create table statement with an additional requirement for a partition key and clustering keys. These keys determine how data in CQL rows are distributed, sorted, and uniquely accessed. Tables in Amazon Keyspaces have the following unique characteristics: Virtually no limit to table size or throughput – In Amazon Keyspaces, a table’s capacity scales up and down automatically in response to traffic. You don’t have to manage nodes or consider node density. Performance stays consistent as your tables scale up or down. Support for “wide” partitions – CQL partitions can contain a virtually unbounded number of rows without the need for additional bucketing and sharding partition keys for size. This allows you to scale partitions “wider” than the traditional Cassandra best practice of 100 MB. No compaction strategies to consider – Amazon Keyspaces doesn’t require defined compaction strategies. Because you don’t have to manage compaction strategies, you can build powerful data models without having to consider the internals of the compaction process. Performance stays consistent even as write, read, update, and delete requirements change. No repair process to manage – Amazon Keyspaces doesn’t require you to manage a background repair process for data consistency and quality. No tombstones to manage – With Amazon Keyspaces, you can delete data without the challenge of managing tombstone removal, table-level grace periods, or zombie data problems. 1 MB row quota – Amazon Keyspaces supports the Cassandra blob type, but storing large blob data greater than 1 MB results in an exception. It’s a best practice to store larger blobs across multiple rows or in Amazon Simple Storage Service (Amazon S3) object storage. Fully managed backups – PITR helps protect your Amazon Keyspaces tables from accidental write or delete operations by providing continuous backups of your table data. The following command creates a table in Amazon Keyspaces by using a cqlsh statement with customer properties specifying on-demand capacity mode, PITR enabled, and AWS resource tags. Using keyspaces-toolkit to connect to Amazon Keyspaces, run this command from within the cqlsh session. CREATE TABLE amazon.eventstore( id text, time timeuuid, event text, PRIMARY KEY(id, time)) WITH CUSTOM_PROPERTIES = { 'capacity_mode':{'throughput_mode':'PAY_PER_REQUEST'}, 'point_in_time_recovery':{'status':'enabled'} } AND TAGS = {'domain' : 'shoppingcart' , 'app' : 'acme-commerce' , 'pii': 'true'}; The preceding command includes the following parameters: capacity_mode – Amazon Keyspaces has two read/write capacity modes for processing reads and writes on your tables. The default for new tables is on-demand capacity mode (the PAY_PER_REQUEST flag). point_in_time_recovery – When you enable this parameter, you can restore an Amazon Keyspaces table to a point in time within the preceding 35 days. There is no overhead or performance impact by enabling PITR. TAGS – Allows you to organize resources, define domains, specify environments, allocate cost centers, and label security requirements. Insert rows Before inserting data, check if your table was created successfully. Amazon Keyspaces performs data definition language (DDL) operations asynchronously, such as creating and deleting tables. You also can monitor the creation status of a new resource programmatically by querying the system schema table. Also, you can use a toolkit helper for exponential backoff. Check for table creation status Cassandra provides information about the running cluster in its system tables. With Amazon Keyspaces, there are no clusters to manage, but it still provides system tables for the Amazon Keyspaces resources in an account and Region. You can use the system tables to understand the creation status of a table. The system_schema_mcs keyspace is a new system keyspace with additional content related to serverless functionality. Using keyspaces-toolkit, run the following SELECT statement from within the cqlsh session to retrieve the status of the newly created table. SELECT keyspace_name, table_name, status FROM system_schema_mcs.tables WHERE keyspace_name = 'amazon' AND table_name = 'eventstore'; The following screenshot shows an example of output for the preceding CQL SELECT statement. Insert sample data Now that you have created your table, you can use CQL statements to insert and read sample data. Amazon Keyspaces requires all write operations (insert, update, and delete) to use the LOCAL_QUORUM consistency level for durability. With reads, an application can choose between eventual consistency and strong consistency by using LOCAL_ONE or LOCAL_QUORUM consistency levels. The benefits of eventual consistency in Amazon Keyspaces are higher availability and reduced cost. See the following code. CONSISTENCY LOCAL_QUORUM; INSERT INTO amazon.eventstore(id, time, event) VALUES ('1', now(), '{eventtype:"click-cart"}'); INSERT INTO amazon.eventstore(id, time, event) VALUES ('2', now(), '{eventtype:"showcart"}'); INSERT INTO amazon.eventstore(id, time, event) VALUES ('3', now(), '{eventtype:"clickitem"}') IF NOT EXISTS; SELECT * FROM amazon.eventstore; The preceding code uses IF NOT EXISTS or lightweight transactions to perform a conditional write. With Amazon Keyspaces, there is no heavy performance penalty for using lightweight transactions. You get similar performance characteristics of standard insert, update, and delete operations. The following screenshot shows the output from running the preceding statements in a cqlsh session. The three INSERT statements added three unique rows to the table, and the SELECT statement returned all the data within the table. Export table data to your local host You now can export the data you just inserted by using the cqlsh COPY TO command. This command exports the data to the source directory, which you mounted earlier to the working directory of the Docker run when creating the alias. The following cqlsh statement exports your table data to the export.csv file located on the host machine. CONSISTENCY LOCAL_ONE; COPY amazon.eventstore(id, time, event) TO '/source/export.csv' WITH HEADER=false; The following screenshot shows the output of the preceding command from the cqlsh session. After the COPY TO command finishes, you should be able to view the export.csv from the current working directory of the host machine. For more information about tuning export and import processes when using cqlsh COPY TO, see Loading data into Amazon Keyspaces with cqlsh. Use credentials stored in Secrets Manager Previously, you used service-specific credentials to connect to Amazon Keyspaces. In the following example, I show how to use the keyspaces-toolkit helpers to store and access service-specific credentials in Secrets Manager. The helpers are a collection of scripts bundled with keyspaces-toolkit to assist with common tasks. By overriding the default entry point cqlsh, you can call the aws-sm-cqlsh.sh script, a wrapper around the cqlsh process that retrieves the Amazon Keyspaces service-specific credentials from Secrets Manager and passes them to the cqlsh process. This script allows you to avoid hard-coding the credentials in your scripts. The following diagram illustrates this architecture. Configure the container to use the host’s AWS CLI credentials The keyspaces-toolkit extends the AWS CLI Docker image, making keyspaces-toolkit extremely lightweight. Because you may already have the AWS CLI Docker image in your local repository, keyspaces-toolkit adds only an additional 10 MB layer extension to the AWS CLI. This is approximately 15 times smaller than using cqlsh from the full Apache Cassandra 3.11 distribution. The AWS CLI runs in a container and doesn’t have access to the AWS credentials stored on the container’s host. You can share credentials with the container by mounting the ~/.aws directory. Mount the host directory to the container by using the -v parameter. To validate a proper setup, the following command lists current AWS CLI named profiles. docker run --rm -ti -v ~/.aws:/root/.aws --entrypoint aws amazon/keyspaces-toolkit configure list-profiles The ~/.aws directory is a common location for the AWS CLI credentials file. If you configured the container correctly, you should see a list of profiles from the host credentials. For instructions about setting up the AWS CLI, see Step 2: Set Up the AWS CLI and AWS SDKs. Store credentials in Secrets Manager Now that you have configured the container to access the host’s AWS CLI credentials, you can use the Secrets Manager API to store the Amazon Keyspaces service-specific credentials in Secrets Manager. The secret name keyspaces-credentials in the following command is also used in subsequent steps. docker run --rm -ti -v ~/.aws:/root/.aws --entrypoint aws amazon/keyspaces-toolkit secretsmanager create-secret --name keyspaces-credentials --description "Store Amazon Keyspaces Generated Service Credentials" --secret-string "{"username":"SERVICEUSERNAME","password":"SERVICEPASSWORD","engine":"cassandra","host":"SERVICEENDPOINT","port":"9142"}" The preceding command includes the following parameters: –entrypoint – The default entry point is cqlsh, but this command uses this flag to access the AWS CLI. –name – The name used to identify the key to retrieve the secret in the future. –secret-string – Stores the service-specific credentials. Replace SERVICEUSERNAME and SERVICEPASSWORD with your credentials. Replace SERVICEENDPOINT with the service endpoint for the AWS Region. Creating and storing secrets requires CreateSecret and GetSecretValue permissions in your IAM policy. As a best practice, rotate secrets periodically when storing database credentials. Use the Secrets Manager helper script Use the Secrets Manager helper script to sign in to Amazon Keyspaces by replacing the user and password fields with the secret key from the preceding keyspaces-credentials command. docker run --rm -ti -v ~/.aws:/root/.aws --entrypoint aws-sm-cqlsh.sh amazon/keyspaces-toolkit keyspaces-credentials --ssl --execute "DESCRIBE Keyspaces" The preceding command includes the following parameters: -v – Used to mount the directory containing the host’s AWS CLI credentials file. –entrypoint – Use the helper by overriding the default entry point of cqlsh to access the Secrets Manager helper script, aws-sm-cqlsh.sh. keyspaces-credentials – The key to access the credentials stored in Secrets Manager. –execute – Runs a CQL statement. Update the alias You now can update the alias so that your scripts don’t contain plaintext passwords. You also can manage users and roles through Secrets Manager. The following code sets up a new alias by using the keyspaces-toolkit Secrets Manager helper for passing the service-specific credentials to Secrets Manager. alias cqlsh='docker run --rm -ti -v ~/.aws:/root/.aws -v "$(pwd)":/source --entrypoint aws-sm-cqlsh.sh amazon/keyspaces-toolkit keyspaces-credentials --ssl' To have the alias available in every new terminal session, add the alias definition to your .bashrc file, which is executed on every new terminal window. You can usually find this file in $HOME/.bashrc or $HOME/bash_aliases (loaded by $HOME/.bashrc). Validate the alias Now that you have updated the alias with the Secrets Manager helper, you can use cqlsh without the Docker details or credentials, as shown in the following code. cqlsh --execute "DESCRIBE TABLE amazon.eventstore;" The following screenshot shows the running of the cqlsh DESCRIBE TABLE statement by using the alias created in the previous section. In the output, you should see the table definition of the amazon.eventstore table you created in the previous step. Conclusion In this post, I showed how to get started with Amazon Keyspaces and the keyspaces-toolkit Docker image. I used Docker to build an image and run a container for a consistent and reproducible experience. I also used an alias to create a drop-in replacement for existing scripts, and used built-in helpers to integrate cqlsh with Secrets Manager to store service-specific credentials. Now you can use the keyspaces-toolkit with your Cassandra workloads. As a next step, you can store the image in Amazon Elastic Container Registry, which allows you to access the keyspaces-toolkit from CI/CD pipelines and other AWS services such as AWS Batch. Additionally, you can control the image lifecycle of the container across your organization. You can even attach policies to expiring images based on age or download count. For more information, see Pushing an image. Cheat sheet of useful commands I did not cover the following commands in this blog post, but they will be helpful when you work with cqlsh, AWS CLI, and Docker. --- Docker --- #To view the logs from the container. Helpful when debugging docker logs CONTAINERID #Exit code of the container. Helpful when debugging docker inspect createtablec --format='{{.State.ExitCode}}' --- CQL --- #Describe keyspace to view keyspace definition DESCRIBE KEYSPACE keyspace_name; #Describe table to view table definition DESCRIBE TABLE keyspace_name.table_name; #Select samples with limit to minimize output SELECT * FROM keyspace_name.table_name LIMIT 10; --- Amazon Keyspaces CQL --- #Change provisioned capacity for tables ALTER TABLE keyspace_name.table_name WITH custom_properties={'capacity_mode':{'throughput_mode': 'PROVISIONED', 'read_capacity_units': 4000, 'write_capacity_units': 3000}} ; #Describe current capacity mode for tables SELECT keyspace_name, table_name, custom_properties FROM system_schema_mcs.tables where keyspace_name = 'amazon' and table_name='eventstore'; --- Linux --- #Line count of multiple/all files in the current directory find . -type f | wc -l #Remove header from csv sed -i '1d' myData.csv About the Author Michael Raney is a Solutions Architect with Amazon Web Services. https://aws.amazon.com/blogs/database/how-to-set-up-command-line-access-to-amazon-keyspaces-for-apache-cassandra-by-using-the-new-developer-toolkit-docker-image/
1 note
·
View note